





 Рейтинг: 4.3/5.0 (1810 проголосовавших)
Рейтинг: 4.3/5.0 (1810 проголосовавших)Категория: Руководства

Уильям Шоттс знакомит вас с истинной философией Linux. Вы уже знакомы с Linux и настала пора нырнуть поглубже и познакомиться с возможностями командной строки.
Командная строка - всегда с вами, от первого знакомства до написания полноценных программ в Bash — самой популярной оболочке Linux. Познакомьтесь с основами навигации по файловой системе, настройки среды, последовательностями команд, поиском по шаблону и многим другим. Прочитав эту книгу вы легко научитесь создавать и удалять файлы, каталоги и символьные ссылки; администрировать систему, включая сетевое оборудование, установку пакетов и управление процессами; редактировать файлы; писать скрипты для автоматизации общих или рутинных задач; выполнять любые работы с текстовыми файлами. Преодолев начальный страх перед оболочкой Linux, вы поймете, что командная страка - это естественный, логичный и простой способ общения с компьютером. И не забывайте протирать пыль с мышки.
Название: Командная строка Linux. Полное руководство
Год издания: 2017
Автор: Уильям Шоттс
Издательство: Питер
Жанр: Компьютерная литература
Количество страниц: 480
Формат: PDF, EPUB
Язык: Русский
Размер: 7.7 Mb
Скачать Уильям Шоттс. Командная строка Linux. Полное руководство
Похожие новости Комментарии (0)Данная книга представляет собой великолепное руководство по Linux, позволяющее получить наиболее полное представление об этой операционной системе. Книга состоит из трех частей, каждая из которых раскрывает один из трех основных аспектов работы с Linux: Linux для пользователя, сетевые технологии Linux (и методика настройки Linux-сервера), программирование Linux. В книге охвачен очень широкий круг вопросов, начиная с установки и использования Linux "в обычной жизни" (офисные пакеты, игры, видео, Интернет), и заканчивая описанием внутренних процессов Linux, секретами и трюками настройки, особенностями программирования под Linux, созданием сетевых приложений, оптимизацией ядра и др.
Изложение материала ведется в основном на базе дистрибутивов Fedora Core (Red Hat) и Mandriva (Mandrake). Однако не оставлены без внимания и другие дистрибутивы SuSe, Slackware, Gentoo, Alt Linux, Knoppix. Дается их сравнительное описание, а по ходу изложения всего материала указываются их особенности. Книга написана известными специалистами и консультантами по использованию Linux, авторами многих статей и книг по Linux, заслуживших свое признание в самых широких Linux-кругах. Если вы желаете разобраться в особенностях Linux и познать ее внутренний мир, эта книга - ваш лучший выбор.
Скачать Linux полное руководство
Майкл Ноэл, Колин Спенс | Microsoft SharePoint 2010. Полное руководство (2012) [PDF]
Автор: Michael Noel, Colin Spence / Майкл Ноэл, Колин Спенс
Название: Microsoft SharePoint 2010 Unleashed / Microsoft SharePoint 2010. Полное руководство
Издательство: Вильямс
ISBN: 978-5-8459-1728-7
Отрасль (жанр): Компьютерная литература
Формат: PDF
Качество: Изначально электронное (ebook)
Страниц: 880, ч/б ил.
Описание:
С помощью технологий Microsoft SharePoint 2010 организации могут собирать, использовать и совместно обрабатывать информацию практически из любого источника. Эта книга представляет собой наиболее полный и практичный ресурс для всех администраторов, менеджеров, архитекторов, пользователей разной степени подготовки, которые хотят получить максимальную отдачу от этой мощной платформы.
В книге рассматриваются все новые возможности SharePoint – от новых компонентов социальных сетей до усовершенствованного поиска – которые помогают максимально задействовать как SharePoint Foundation, так и SharePoint Server 2010. На понятных пошаговых примерах авторы разъясняют, как упростить администрирование, оптимизировать производительность, управлять затратами и реализовать ценные решения сотрудничества, управления документами и бизнес-логики.
Время раздачи: До 3-х сидов
Оцените книгу! →
 Название: LINUX: полное руководство.
Название: LINUX: полное руководство.
Год выпуска: 2006
Автор: Колисниченко Д.Н. Аллен Питер В.
Издательство: Наука и Техника,
ISBN: 5-94387-139-Х
Формат. PDF
Количество страниц: 784
Язык: Русский
Размер: 94Мб
Краткое описание: Данная книга представляет собой великолепное руководство по Linux, позволяющее получить наиболее полное представление об этой перационной системе. Книга состоит из трех частей, каждая из которых раскрывает один из трех сновных аспектов работы с Linux: Linux для пользователя, сетевые технологии Linux (и методика настройки Linux- сервера), программирование Linux. В книге охвачен очень широкий круг вопросов, начиная с установки и использования Linux «в обычной жизни» (офисные пакеты, игры, видео, Интернет), и заканчивая описанием внутренних процессов Linux, секретами и трюками настройки, особенностями программирования под Linux, созданием сетевых приложений, оптимизацией ядра и др. Изложение материала ведется в основном на базе дистрибутивов Fedora Core (Red Hat) и Mandriva (Mandrake). Однако не оставлены без внимания и другие дистрибутивы SuSe, Slackware, Gentoo, Alt Linux, Knoppix. Дается их сравнительное описание, а по ходу изложения всего материала указываются их особенности. Книга написана известными специалистами и консультантами по использованию Linux, авторами многих статей и книг по Linux, заслуживших свое признание в самых широких Linux-кругах. Если вы желаете разобраться в особенностях Linux и познать ее внутренний мир, эта книга — ваш лучший выбор.
Если какая либо из ссылок не работает, отметьте галочкой какая сылка битая и нажмите кнопку “Битая ссылка”, и через пару часов, ссылка будет вновь работать.
(Fb2-info) (ссылка для форума) (ссылка для блога) (QR-код книги)
[url=http://coollib.com/b/226675]
[b]Linux: Полное руководство (fb2)[/b]
[img]http://coollib.com/i/75/226675/img_0.jpeg[/img][/url]
Данная книга представляет собой великолепное руководство по Linux, позволяющее получить наиболее полное представление об этой операционной системе. Книга состоит из трех частей, каждая из которых раскрывает один из трех основных аспектов работы с Linux: Linux для пользователя, сетевые технологии Linux (и методика настройки Linux-сервера), программирование Linux. В книге охвачен очень широкий круг вопросов, начиная с установки и использования Linux «в обычной жизни» (офисные пакеты, игры, видео, Интернет), и заканчивая описанием внутренних процессов Linux, секретами и трюками настройки, особенностями программирования под Linux, созданием сетевых приложений, оптимизацией ядра и др.
Изложение материала ведется в основном на базе дистрибутивов Fedora Cora (Red Hat) и Mandriva (Mandrake). Однако не оставлены без внимания и другие дистрибутивы SuSe, Slackware, Gentoo, Alt Linux, Knоppix. Дается их сравнительное описание, a по ходу изложения всего материала указываются их особенности.
Книга написана известными специалистами и консультантами по использованию Linux, авторами многих статей и книг по Linux, заслуживших свое признание в самых широких Linux-кругах. Если вы желаете разобраться в особенностях Linux и познать ее внутренний мир, эта книга — ваш лучший выбор.
HDInsight Services for Microsoft Azure — это сервис, позволяющий работать с кластером Apache Hadoop в Облаке, предоставляющий программную среду для операций управления, анализа и отчетности по Большим Данным.
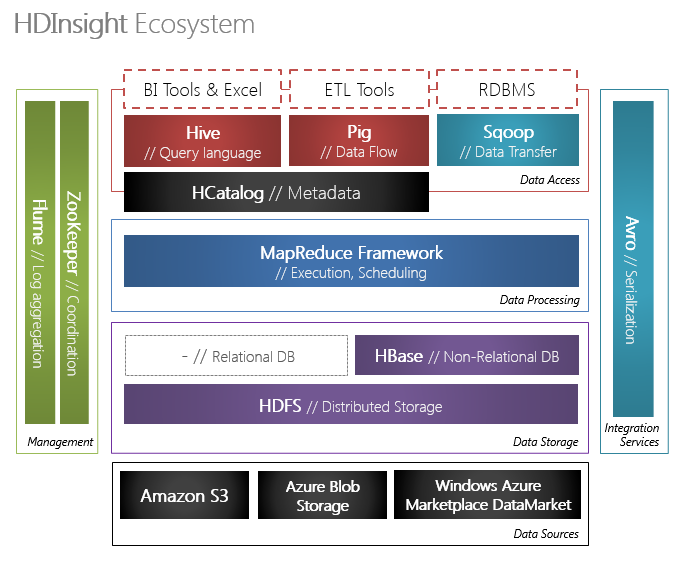
Я не буду подробно останавливаться на возможностях Hadoop. Он был впервые представлен в 2005 г. в составе проекта Apache Software Foundation и представляет собой программную платформу распределенной обработки значительных объемов данных. Скажем, петабайтный размер не является для нее препятствием. Платформа Hadoop основана на распределенной файловой системе HDFS (Hadoop Distributed File System), реализованной на кластере Hadoop. В состав кластера входят узлы, хранящие фрагменты файлов (DataNode). Теоретически могут быть сотни и тысячи таких узлов, основанных на недорогих вычислительных платформах (commodity hardware). Для обеспечения высокой надежности поддерживается избыточность путем создания копий фрагментов между узлами. Знаниями о том, на каком узле данных какая реплика лежит, обладает NameNode. Со стороны клиента это выглядит, как обычная древовидная файловая система. Сам NameNode не выполняет основные операции ввода-вывода. Он лишь снабжает клиента метаданными о местоположении первичной реплики фрагмента. Репликация фрагментов осуществляется автоматически. В случае выхода из строя первичной реплики фрагмента одна из его вторичных реплик назначается первичной и на дополнительном узле также автоматически создается еще одна копия. Масштабируемость на значительные объемы данных достигается за счет параллельной обработки фрагментов. Исторически в разработке Google Labs проект Hadoop был ориентирован на задачи поиска и классификации Интернет-контента. Например, функция Map получает на вход набор данных и преобразует его в список пар ключ/значение. Функция Reduce выполняет обратную операцию, сворачивая список путем группировки его по ключам. В целях распараллеливания может быть создано множество экземпляров таких функций, каждый обрабатывающий свой фрагмент. Узлы, на которых хранятся входные фрагменты файлов и запускаются обрабатывающие их экземпляры MapReduce, носят название TaskTracker, а координирующий экземпляры узел – JobTracker. Количество экземпляров определяется количеством и местоположением фрагментов. Помимо поисковых, под данный шаблон попадает множество иных типов задач обработки данных. Существуют построенные поверх HDFS и MapReduce проекты Pig, Hive, Mahout, Pegasus и др. предоставляющие более высокий уровень абстракции и позволяющие решать задачи управления потоками данных, запросные, аналитические задачи, а также задачи отыскания скрытых закономерностей (data mining), характерные для хранилищ (data warehouses), которые традиционно строятся на серверах управления базами данных, реляционной модели и того или иного диалекта языка запросов SQL. Взаимодействие не менее традиционно осуществляется при помощи ODBC-драйверов.
Осенью прошлого года на конференции Pass Summit 2011 в Сиэтле было объявлено о выпуске Hadoop Connector для Microsoft SQL Server, облегчающего обмен данными между двумя системами. Кроме того, в партнерстве с компанией HortonWorks в настоящее время предоставляется предварительная ознакомительная версия Microsoft Azure HDInsight Service и Microsoft HDInsight Server for Windows, 100%-совместимая с открытыми стандартами Apache Hadoop. Скачать HDInsight Server под Windows можно здесь. Чтобы попробовать HDInsight Service в Облаке, нужно зарегистрироваться на тестирование здесь .
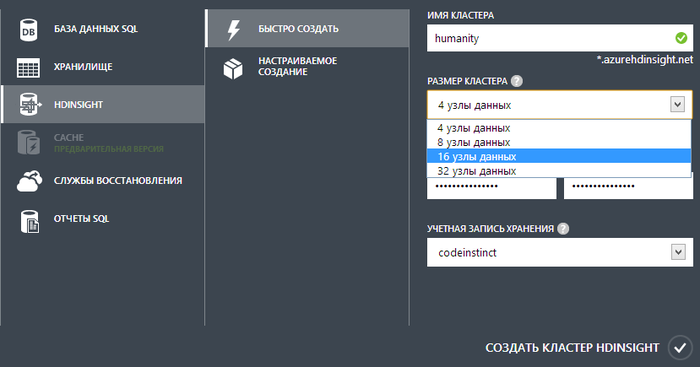
В качестве пререквизитов необходимо иметь облачную учетную запись Microsoft. Эккаунты в рамках программ MSDN, BizSpark, DreamSpark работают. В рамках предварительной версии доступно создать кластер Hadoop из 3-х узлов с общим объемом дискового пространства 1.5 ТБ. Кластер будет жить 5 суток с момента создания. После этого вся конфигурация и содержимое будут потеряны, придется создавать заново. Из начальных данных требуется указать DNS-имя (оно, понятно, должно быть уникальным) и административный логин/пароль. Использование Microsoft Azure SQL Database для хранения метаданных нам на первых порах не понадобится, но на всякий случай обратите внимание, что такая возможность есть и база (в том случае, если вы захотите ей воспользоваться) должна быть создана заранее. Жмем на кнопку Request Cluster в правой нижней части экрана:
Проходит несколько минут, и Cluster Status = Deploying изменяется на Running, после чего его можно использовать.
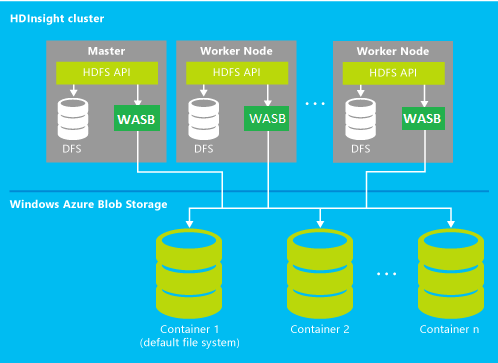
Жмем на ссылку Go to Cluster. Из Web-интерфейса можно перейти в интерактивная консоль выполнения JavaScript и Hive-команд, сессию удаленного доступа, сконфигурировать порты для взаимодействия по ODBC, создать задание, посмотреть историю выполнения заданий, ознакомиться с типовыми примерами использования Hadoop. По кнопке Downloads в настоящее время имеется возможность установить на локальную машину x86 или х64 HiveODBC-драйверы. Кнопка Manage Cluster позволяет контролировать размер использованного дискового пространства, а также задать папки в Microsoft Azure BLOB Service, которые можно рассматривать как сторидж (Azure Storage Vault), альтернативный дисковому пространству кластера для нативных процессов Hadoop. Например, в качестве входного и выходного местоположения для MapReduce. Если что-то фатально напортачили, кластер можно пересоздать, зайдя на www.hadooponazure.com/ и нажав кнопку Release Cluster.
Установим соединение через Remote Desktop, кликнув на соответствующую плитку в экране портала. Для авторизации используется учетная запись, заданная на Рис.1.
Можно видеть, что в качестве базовой операционной системы используется 64-битная редакция Windows Server 2008R2 Enterprise SP1. Она установлена на партиции D. Для открытия командного окна Hadoop запустим Start -> Run ->
D:\Windows\system32\cmd.exe /k pushd
Создадим в HDFS каталог для будущих экспериментов и подкаталог, куда будут размещены входные данные:
hadoop fs -mkdir Sample1/input
Для получения интерактивной справки java FsShell следует набрать hadoop fs -help.
Перенесем в подкаталог input файл Sample.log, который понадобится для дальнейшей иллюстрации работы Hadoop. Этот файл представляет собой некоторый абстрактный журнал слабоструктурированного формата, содержащий строки с признаками TRACE, DEBUG, INFO, FATAL и т.д. Его можно взять из примеров HortonWorks по адресу gettingstarted.hadooponazure.com/hw/sample.log. Это не терабайтный лог, он имеет скромный размер
100 КБ, но для иллюстрации, скажем, MapReduce сгодится. Для простоты скачаем его начально в директорию Windows на кластере HDInsight, скажем, d:\Temp. Интернет на Windows-машине, с которой установлено удаленное подключение, имеется. Сразу будет предложено обновить Internet Explorer, но для наших последующих задач это несущественно. Загрузим Sample.log в HDFS. Для копирования из локальной файловой системы используется свитч -put:
Убеждаемся, что он загрузился:
hadoop fs -ls Sample1/input/
Далее будут рассмотрены базовые возможности MapReduce на примере анализа Sample.log
Автор статьи: Алексей Шуленин.

Название. Excel 2013. Полное руководство (+ DVD)
Автор. В. Серогодский, Р. Прокди, А. Рогозин, Д. Козлов, А. Дружинин
Издательство. Наука и техника
Год. 2015
Жанр. Компьютерная литература
Формат. PDF+DVD (PPTX)
Страниц. 415
Описание :
С этой книгой вы научитесь грамотно пользоваться профессиональными возможностями Excel 2013, сможете существенно повысить эффективность своей работы и научитесь быстро решать самые различные задачи. Особое внимание уделено таким важным вопросам, как проведение расчетов (от решения алгебраических уравнений до использования спец. функций Excel и применения мегаформул), оформление данных (построение всевозможных графиков и диаграмм), использование сводных таблиц, особенности проведения анализа и выявления различных закономерностей в данных. Книга рассчитана на самый широкий круг читателей. Ведь все пользуются Ехсеl'ем, но в большинстве случаев делают это неумело или попросту не знают, как что-то сделать в нем. Книга написана простым и доступным языком. Приводится огромное количество наглядных примеров. На прилагаемом DVD размещены 7 обучающих курсов по трюкам и спец.приемам, практике проведения разного рода вычислений и анализу данных в Excel 2010-2013, а также обновления для Microsoft Office 2013.
Для того, чтобы вы могли проходить обучающие курсы, у вас на компьютере должна быть установлена программа Microsoft PowerPoint 2010, входящая в состав пакет Microsoft Office (в этот пакет входит и программа Excel).
Именно в Microsoft PowerPoint открывается обучающий курс при запуске.
Если у вас такой программы нет, то вы можете вместо нее воспользоваться программой PowerPointViewer, размещенной в соответсвующей папке на диске. Программа является бесплатной.





Azure HDInsight представляет собой расширение Apache Hadoop на основе облачных технологий. Это подразумевает возможность обработки любого объема информации с масштабированием от терабайтов до петабайтов данных по запросу. Запускайте любое количество узлов в любое время. Плата взимается только за те вычислительные ресурсы и хранилища, которые используются.

Требования к аудиту предусматривают хранение данных в течение семи лет, а некоторая информация должна храниться целых 30 лет. Используя HDInsight, мы можем хранить больше данных и обращаться к ним при необходимости.
–Дон Вуд (Don Wood), Бет Израэль (Beth Israel), медицинский центр Deaconess


HDInsight полностью совместим с Apache Hadoop и поэтому может обрабатывать неструктурированные или частично структурированные данные журналов посещений сайта, социальных сетей, журналов серверов, устройств, сенсоров и т. д. Благодаря этому можно анализировать новые наборы данных и находить новые возможности для бизнеса, которые будут способствовать росту вашей организации.

При помощи решения, основанного на SQL Server и службе Azure HDInsight, мы можем захватывать данные, написанные на обычном разговорном языке, и использовать их для улучшения предоставляемых услуг?В будущем это позволит, например, полностью пересмотреть методы обработки медицинских записей.
–Пол Хендерсон (Paul Henderson), Ascribe
Разрабатывайте программное обеспечение на предпочитаемом вами языкеHDInsight имеет эффективные программные расширения для языков, включая C#. Java и .NET. Используйте выбранный вами язык программирования на Hadoop для создания, настройки, отправки и контроля заданий Hadoop. Дополнительно


С помощью HDInsight можно разворачивать Hadoop в облаке без покупки нового аппаратного обеспечения и других первоначальных затрат. Также не требуется длительная установка и настройка. В Azure подготовка к началу работы происходит быстро и без каких-либо усилий с вашей стороны. Первый кластер можно запустить в считаные минуты.

Гибкость облака в Azure позволяет не беспокоиться о настройке инфраструктуры и масштабировании центров обработки данных.
–Суджатха Байяпуредди (Sujatha Bayyapureddy), McKesson
Используйте Excel или предпочтительное средство бизнес-аналитики для визуализации данных HadoopИнтеграция HDInsight с Excel позволяет визуализировать и анализировать данные Hadoop новыми способами при помощи инструмента, хорошо известного бизнес-пользователям. В Excel пользователи могут выбрать Azure HDInsight в качестве источника данных.

Я изучал другие решения бизнес-аналитики на рынке, и в большинстве своем они оказались слишком сложными, в особенности с точки зрения пользователя.
–Эндрю Чонг (Andrew Cheong), BlackBall


HDInsight также интегрирован с платформой данных Hortonworks. поэтому можно перемещать данные Hadoop из локального центра обработки данных в облако Azure для архивации, разработки и тестирования и сценариев перевода нагрузки из частного облака в общедоступное. С помощью платформенной системы аналитики Майкрософт можно одновременно отправлять запросы в локальные и облачные кластеры Hadoop.
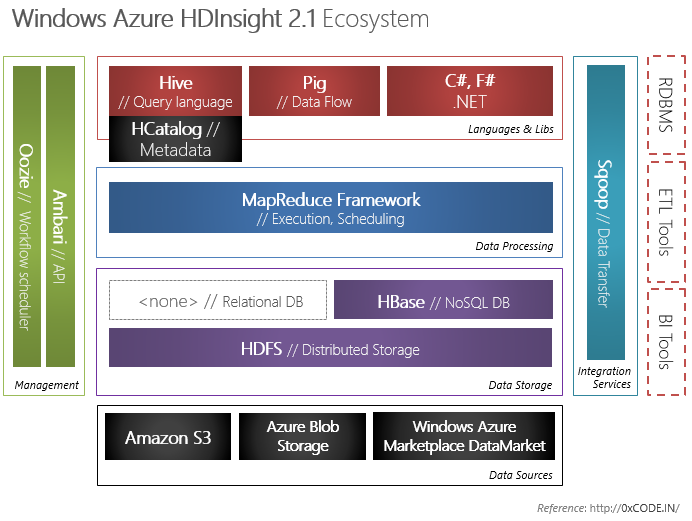
Настроить кластеры для запуска других проектов Hadoop.Экосистема Apache Hadoop — это портфель легко переносимых проектов с открытым кодом, которые быстро развиваются. Служба HDInsight способна разворачивать произвольные проекты Hadoop при помощи пользовательских скриптов. Пример — проекты Spark, R, Giraph и Solr.


HDInsight также включает в себя Apache HBase, столбчатую базу данных NoSQL, работающую на базе распределенной файловой системы Hadoop (HDFS). Это позволяет обрабатывать большие транзакции с нереляционными данными, реализуя интерактивные веб-сайты или записывая информацию с датчиков в хранилище больших двоичных объектов Azure.
Обработка потоков в реальном времениHDInsight включает Apache Storm, потоковую платформу аналитики, способную обрабатывать множество событий в реальном времени. Это позволяет обрабатывать миллионы событий по мере их появления, что дает возможность реализовать такие варианты использования, как Интернет вещей (IoT), и вести аналитику по данным с подключенных устройств или на основе действий пользователей в Интернете. Мы упрощаем развертывание и реализацию Storm. Подробнее о Storm


HDInsight включает Apache Spark, проект с открытым исходным кодом в экосистеме Apache, который может выполнять крупномасштабные приложения анализа данных в памяти. Spark обрабатывает запросы до 100 раз быстрее, чем традиционные запросы больших данных. Apache Spark использует общую модель для выполнения задач, например ETL, запросов пакетной службы, интерактивных запросов, потоковой передачи в реальном времени, машинного обучения и обработки данных из службы хранения Azure с использованием графов. Подробнее о Spark
Используйте R для прогнозного моделирования и машинного обученияHDInsight включает R Server для Hadoop, реализацию одного из самых популярных языков программирования для статистических вычислений и машинного обучения с горизонтальным масштабированием. R Server на базе HDInsight является облачной реализацией языка R со стопроцентно открытым кодом, интегрированной с кластерами Hadoop и Spark. Таким образом, вы можете использовать знакомые возможности языка R, подкрепленные масштабируемостью и производительностью Hadoop. Подробнее об R Server для HDInsight см. здесь.


При развертывании рабочих нагрузок по обработке больших данных в Microsoft Azure можно выбрать кластеры Linux или Windows. При выборе Windows можно пользоваться существующим кодом на базе Windows, включая .NET, для охвата всех своих данных, находящихся в Azure. При выборе Linux клиентам проще перемещать существующие рабочие нагрузки Hadoop в облако и внедрять дополнительные компоненты по работе с большими данными, которые могут выполняться в службе. Предлагая на выбор кластеры Windows и Linux, Майкрософт повышает уровень гибкости для клиентов, давая им возможность формировать значимую информацию на основе громадных объемов данных, создаваемых в облаке, с помощью ОС по своему выбору.
*Hadoop и его логотип с изображением слона являются охраняемыми товарными знаками Apache Software Foundation.
Клиенты, реализующие Hadoop в Azure





Find and deploy popular applications from trusted Hadoop partners available in the Azure Marketplace .








